




最近服务器瞬时流量比较大,经常出现某进程无缘无故被干掉了的情况。
寻找现场:
一、日志:
/var/log/syslog

说的是运行内存不足导致程序运行失败了
二、上阿里云看监控:
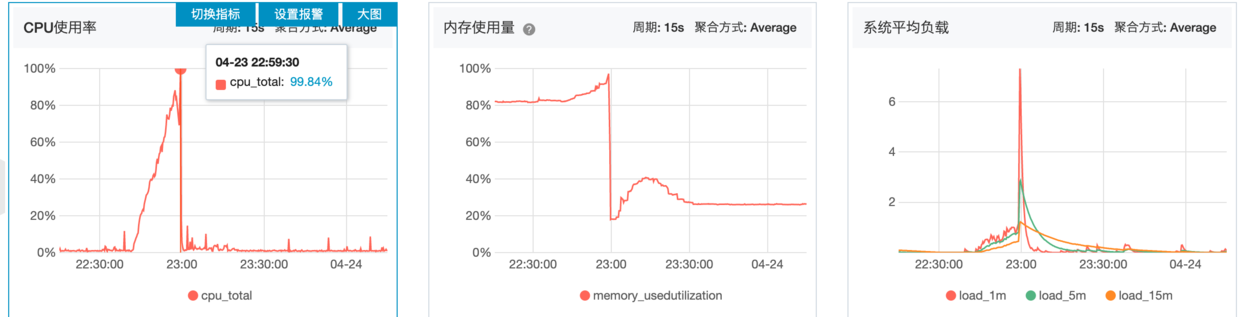
显示服务器几个关键数据直接达到了最大值
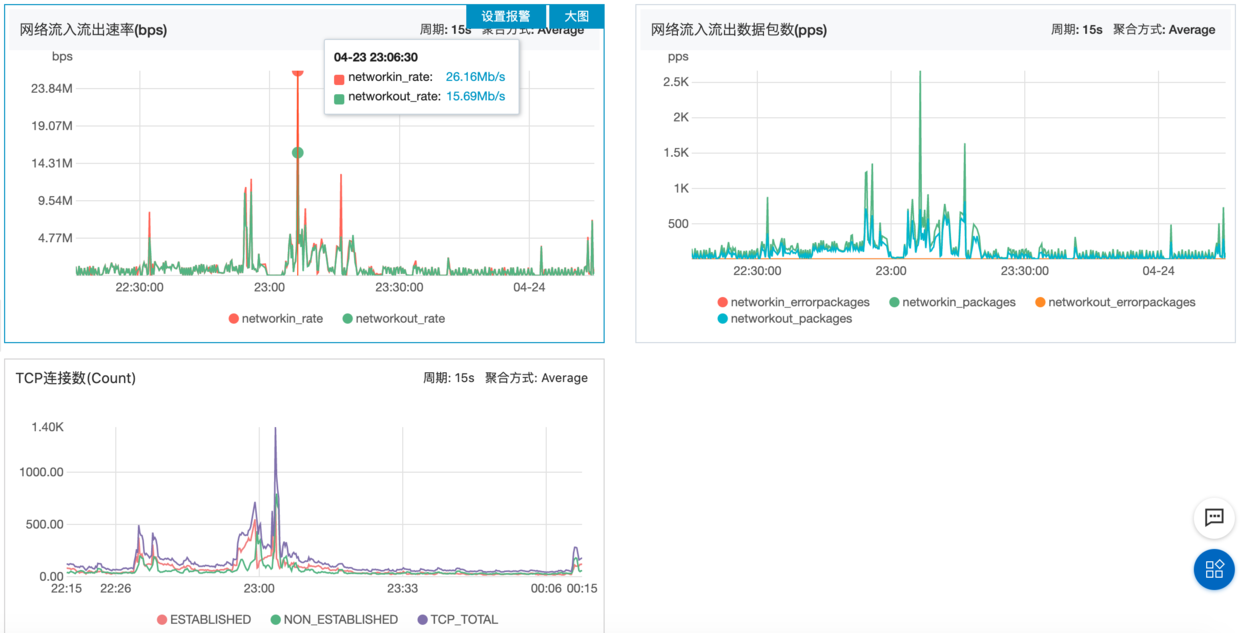
显示网络流入流出非常高
但是从这些监控中根本看不出来是因为什么原因导致的内存不足,实际情况是进程被杀死了。结合服务器业务场景猜测一下。
三、业务场景:
将 a 程序的流量通过本地端口发到 b 程序,由 b 程序处理。
就是这么简单的一个过程,由于 b 程序的处理效率跟不上 a 程序转发来的数据量,导致数据积压越来越多,堆在 a 程序的运行内存中,直接引发了 a 程序占用内存过多,触发了 liunx OOM_killer 。
四、liunx 自我保护机制
原因:内存不足唤醒 oom_killer ,挑出 /proc/<pid>/oom_score 最大者并将之 kill 掉。
那么需要找出真正执行的过程是什么
参考文章 https://stackoverflow.com/questions/726690/what-killed-my-process-and-why
说到了 由于outofmemory被kill掉的进程,会在/var/log下的某个文件中留下最终的痕迹
运行
cd /var/log
dmesg -T | grep -E -i -B100 'killed process'
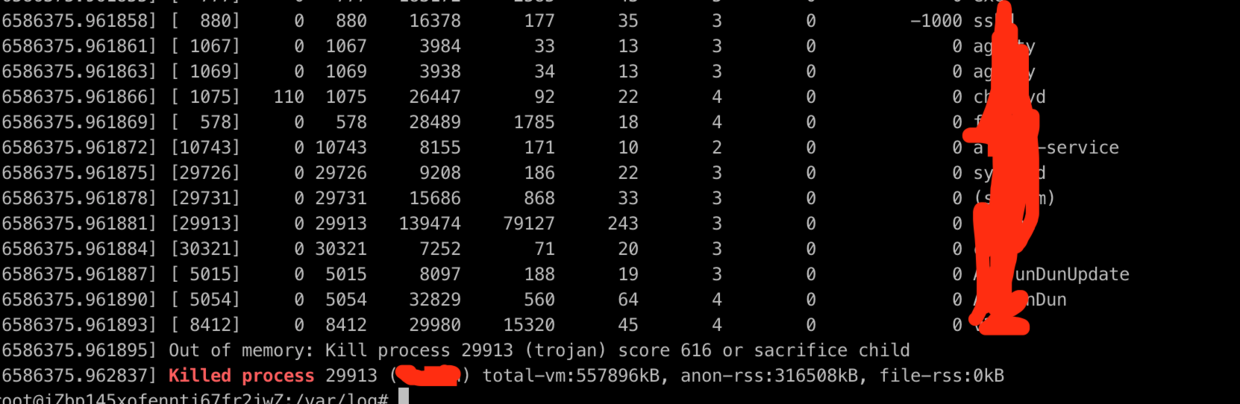
找到了被 kill 的过程
网络途径搜到了以下方式(未验证):
保护进程不被 oom_killer 杀死
-
选择一个进程保护:
echo -17 > /proc/<pid>/oom_adj,-17 -
禁用整个系统的
OOM
sysctl -w vm.panic_on_oom=1 (默认为0,表示开启)
sysctl -p
有些时候 free -m 时还有剩余内存,但还是会触发 OOM-killer,考虑是否 buff/cache 占用过多
附上一个定时脚本清理
buff/cache
echo "0 * * * * root echo 3 > /proc/sys/vm/drop_caches" >> /etc/crontab # 1小时一次 清除页面缓存,目录项和inode
service cron restart
到此一个进程莫名被终结的原因找到了,更加深入的问题,需要研究一下 OOM-killer

评论区